Building a Lithuanian Law Assistant with LLM and RAG (part 1)
I'm building another one, a new app. This time I'll share my progress and findings with you. I'm building a Lithuanian law assistant with LLM using RAG. As nowadays usual, it is a chat interface which must be aware of multiple Lithuanian law entities and relationships between...
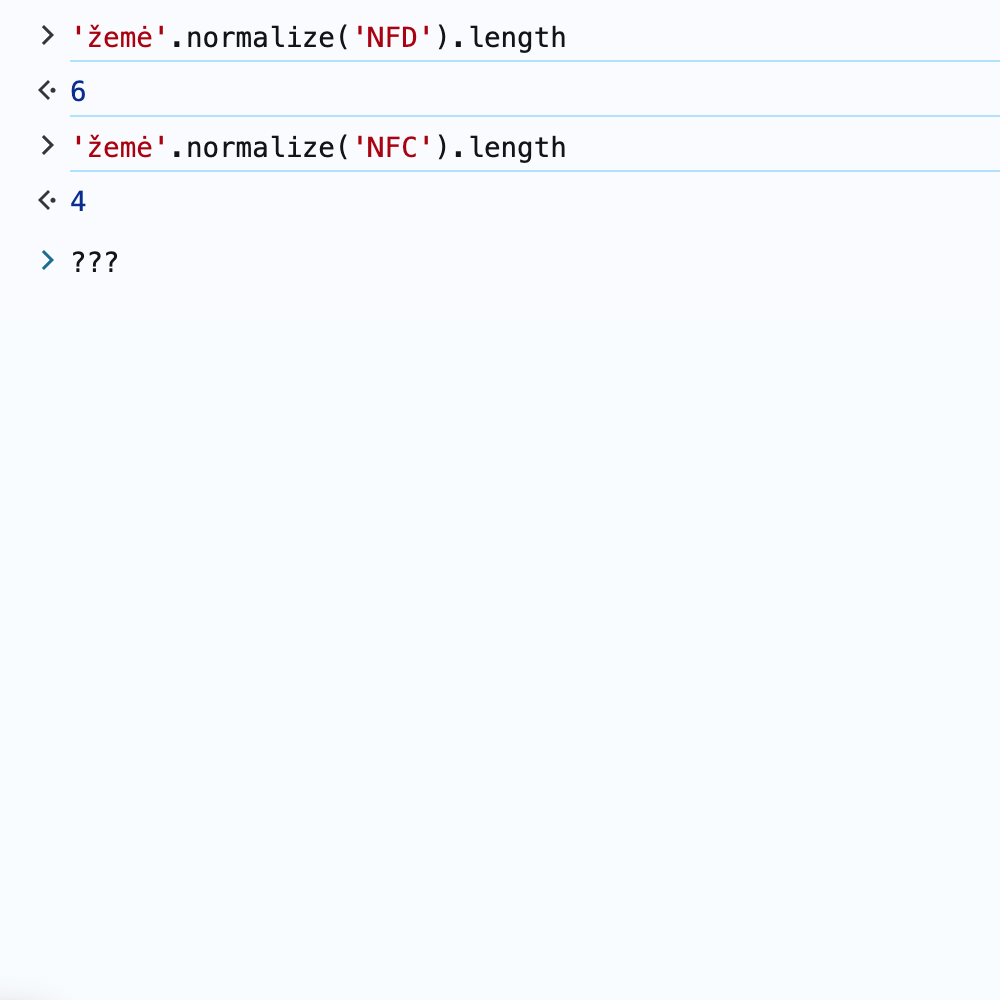
Related concepts: Building a Lithuanian Law Assistant with LLM and RAG (part 2) , RAG , Lithuanian Lemmatization: A Practical Guide , Normalizing Diacritics in Lithuanian .
I'm building another one, a new app. This time I'll share my progress and findings with you. I'm building a Lithuanian law assistant with LLM using RAG. As nowadays usual, it is a chat interface which must be aware of multiple Lithuanian law entities and relationships between them to answer questions: how is this law act's paragraph applied in practice? What are the consequences? What is the process? I genuinely believe that this application will be useful and the application of LLM + RAG is a good fit here (let me know if you think the opposite).
Tech Stack
PostgreSQL + Prisma
Node.js + NestJS
Vite, React (Radix UI components)
Vitest, pnpm, TypeScript
Models: text-embedding-3-small, gpt-4o-mini
I am using NestJS for the first time. First impression: this is a Java Spring framework implemented in TypeScript. It has a rich ecosystem, and for now it is a good fit for a small project.
What I've Done So Far
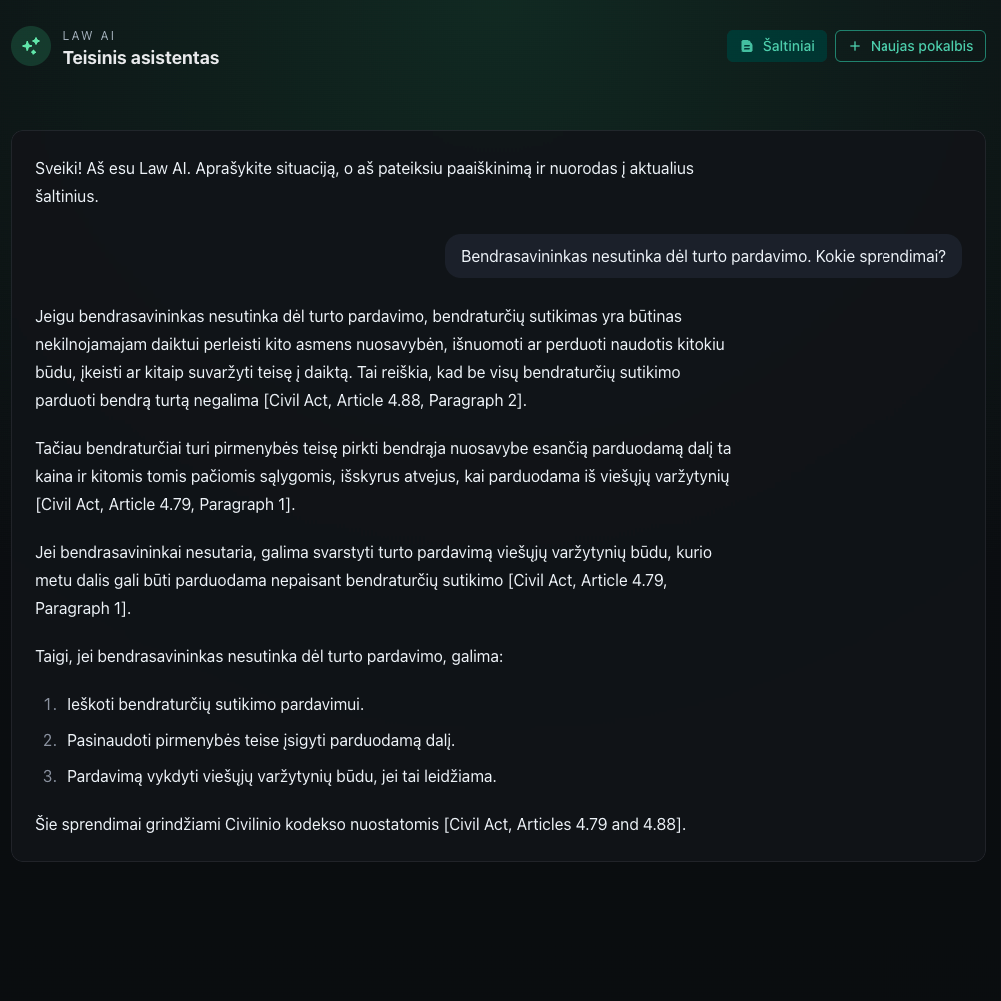
I have a chat interface in dark theme with calming green elements. I haven't encountered any complexity with the UI at all. It is simple and it has one screen.
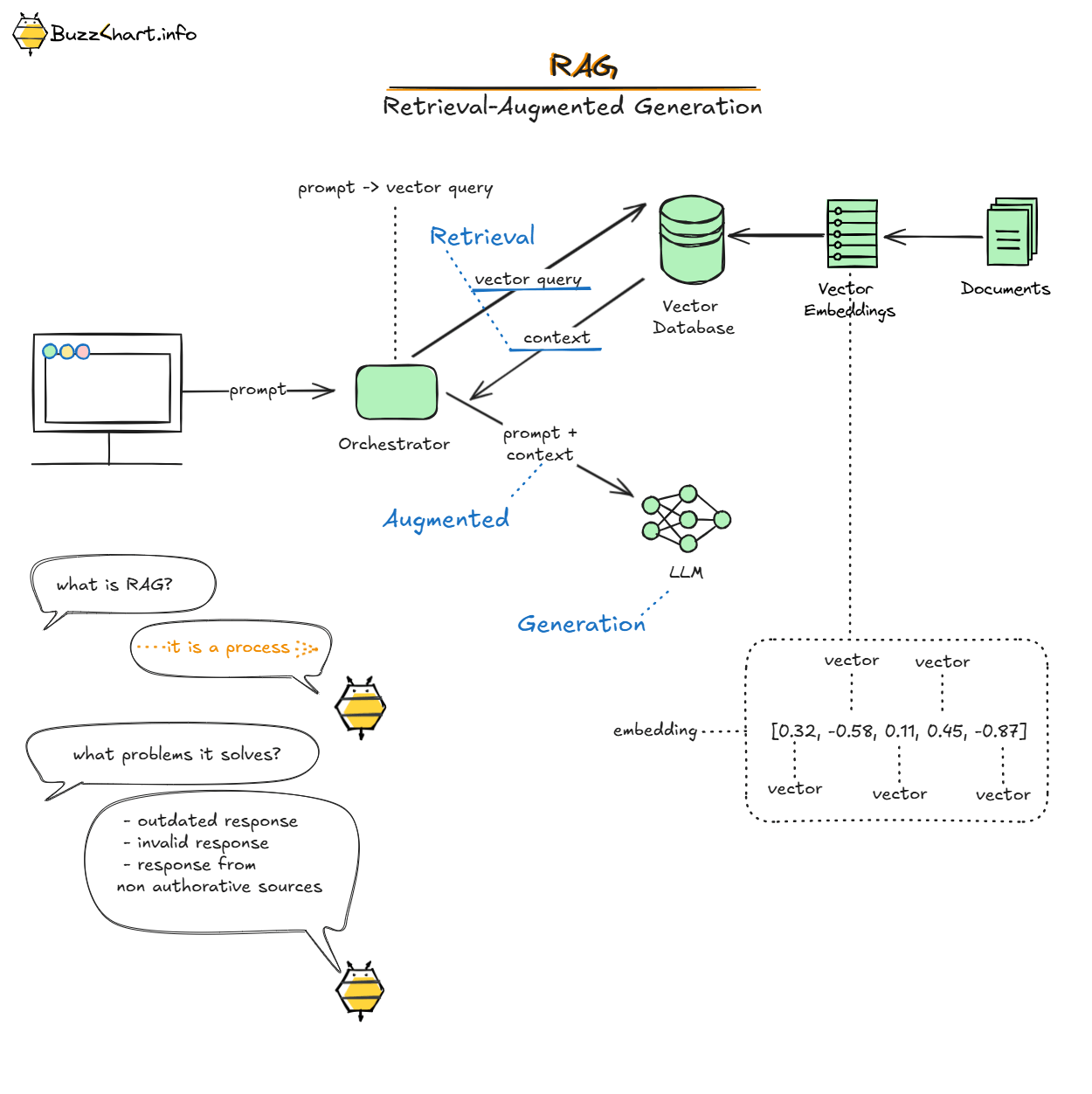
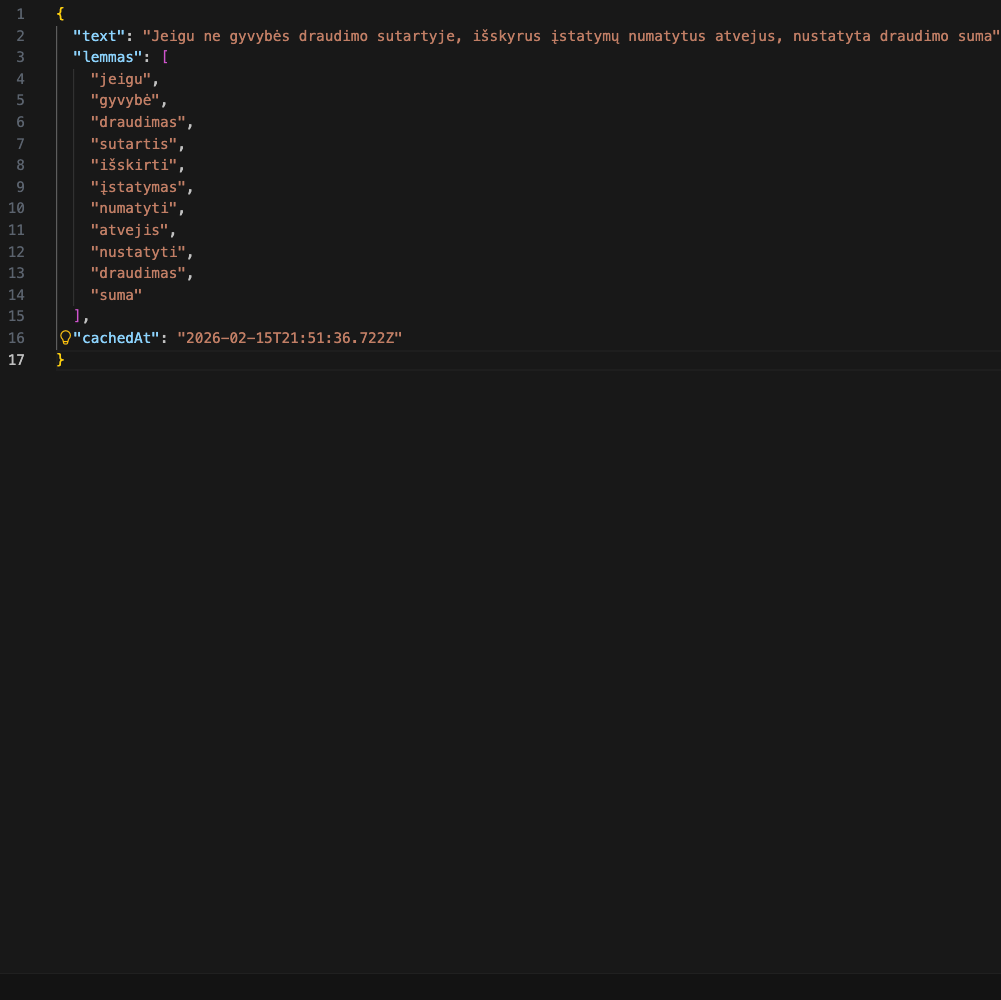
I've learned the ingestion pipeline meaning. Very important part of the application. One of the most important. What is ingestion? This is a process of transforming any data to structured data with embeddings (vectors) for later retrieval. The quality and accuracy of responses depends on the quality of data. For example, you want to ingest labor law. Then you need to find one, export it as any type of artifact (docx, pdf, html), parse it to text (I've chosen markdown), and then chunk it to entities (act → article → paragraph), create embeddings for those chunks and save embeddings to the database.
Parsing and Chunking
Currently parsing and chunking are the most time-consuming tasks for me. Current implementation can ingest any Lithuanian act (act → article → paragraph). This step requires thorough testing and multiple iterations. At this point regular expressions are my solution for parsing and chunking.
Conversation
For conversation I'm doing the following:
Combining history to one prompt - the tradeoff: multiple LLM calls and longer response time, but more accurate context augmentation
Get embeddings for this prompt
Query my chunks by embedding - I store only paragraph chunks, because article chunks may be too long, so I've omitted embedding article as a whole. Though I store reference to an article
Query LLM with chat history (last 12 messages) + chunks from DB - not sure that 12 last messages is a good solution here. But I need to make a decision how to prevent context overflow
For now this process works as expected for chat interface. Response time is acceptable, but database and servers are deployed locally. Deployed application latency may add some milliseconds. At this point it is fast enough.
What Are My Next Steps?
I will work on expanding the domain, adding legal documents, procedures, institutions, decisions, concepts, principles and consequences. This is not the hardest "business" domain. But for me there is a lot what I should learn first.
Adding new entities to the application requires:
Understanding why it is important
Understanding what this entity does
Parsing and chunking data
Storing and linking to existing domain entities