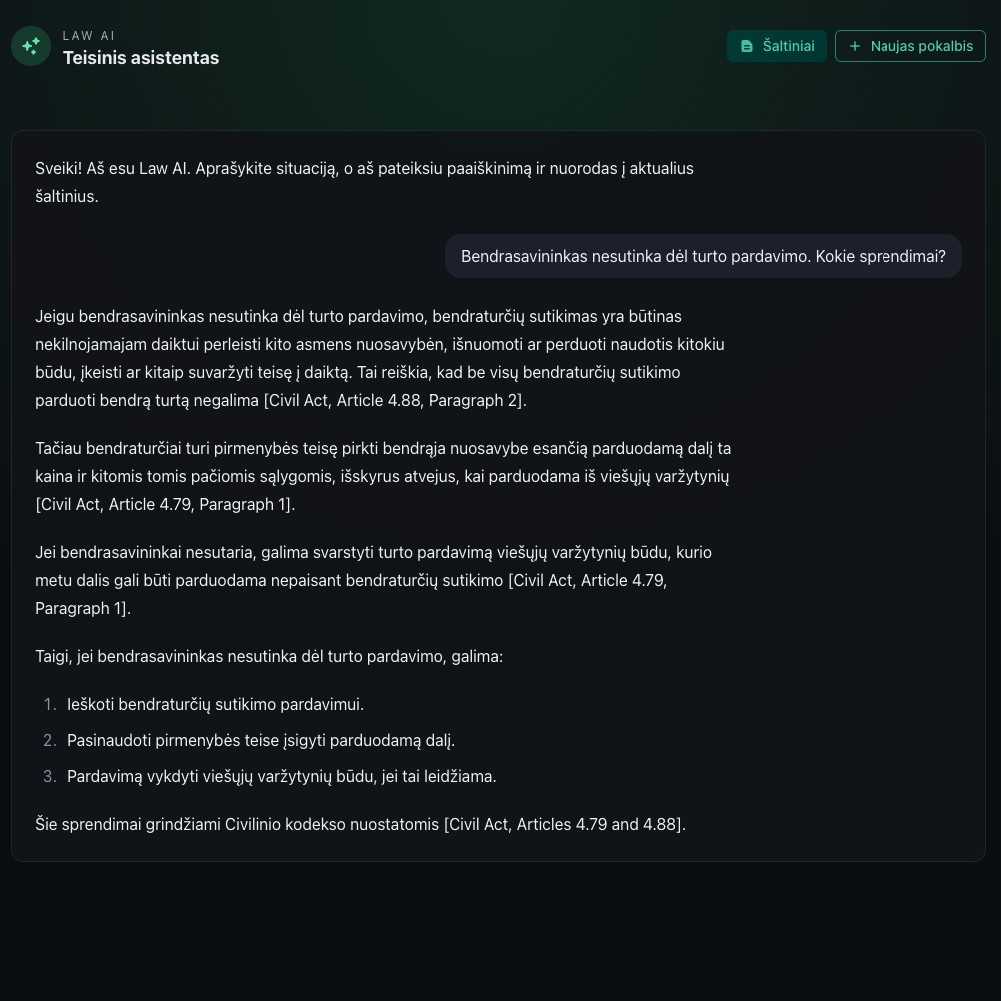
From 6GB and 156 million lines down to 921 laws in 13 minutes. Here's how I filtered Lithuania's legal archive.
I continue building a law assistant app and documenting the progress along the way. Now I've decided to get a finite list of law documents. Not to guess which is important and which is not.
Collecting Data
First challenge was to collect data. I found 6GB of laws. Multiple formats are exposed: HTML, CSV, JSON, JSONL, ASCII, RDF. I chose CSV.
I'm parsing this CSV line by line. Chunking legal documents by CSV header with id and document type.
The solution is to read the document line by line (hundreds of millions of lines) and chunk by metadata header. Metadata header contains "id" and multiple other attributes, not always containing values.
With the data structure understood, the next challenge was determining what to keep and what to discard.
Filtering
This archive contains multiple legal documents. I need only important ones. For now I want laws only. I do not want amendments (duplications in actual redaction of law), regulations, decrees, resolutions, orders, protocols, international law ratifications. Only laws. And law is a form of a document. Ratification is a law legalizing international law. So I need only local laws for now.
Once I knew what to filter, I needed to extract consistent metadata from inconsistent sources.
Normalizing Data
For a legal document, I want to have document name, document type, and effective date at least. Spoiler alert: metadata does not contain this data in most cases. And document type is my internal type for filtering.
With clarity on what data I needed, the bottleneck became how fast I could process it.
Performance
In parsing 6GB of data, performance is important. Whether parsing takes 10 minutes or 100 minutes is a big difference at the prototype level. After normalizing, filtering, and refactoring, I ended up with 30 seconds per million lines. And I have hundreds of millions of lines (156 million to be precise).
Quick win for me was to ask an LLM to inspect node performance snapshot:
-
node --prof <your command>creates v8 performance logs -
node --prof-processtransforms these logs to readable profiler snapshot
Then the LLM found hotspots and optimized those. The key optimization was using a bitmask (similar to a Bloom filter) for fast document type filtering. Instead of string comparisons for every line, I create a character mask:
function maskForLetters(value: string): number { let mask = 0; for (let i = 0; i < value.length; i += 1) { const code = value.charCodeAt(i); if (code >= 97 && code <= 122) { mask |= 1 << (code - 97); } else if (code >= 65 && code <= 90) { mask |= 1 << (code - 65); } } return mask; }
Then filter lines with a simple bitwise operation:
typescript
if ((lineMask & type.firstCharMask) === 0) continue;
This reduced processing time from 30 seconds to 5 seconds per million lines. Total processing time for 156 million lines: around 13 minutes.
Summary
As a result, I have 921 "important" laws extracted, with document name, effective date, and a link to the archive. The next step is defining a data model and parsing the important laws.