Normalizing Diacritics in Lithuanian
Lithuanian writing system reflects this richness through extensive use of diacritical marks. The Lithuanian alphabet contains 32 letters , including several with diacritics that don't appear in many other languages.
Related concepts: Building a Lithuanian Law Assistant with LLM and RAG (part 2) , Building a Lithuanian Law Assistant with LLM and RAG (part 1) , ACID in Database Transactions , Radix UI: A Modern Headless Component Library (LLM-Research) .
Lithuanian Diacritics
Lithuanian writing system reflects this richness through extensive use of diacritical marks. The Lithuanian alphabet contains 32 letters, including several with diacritics that don't appear in many other languages.
Unique Lithuanian Characters
Lithuanian uses multiple diacritical letter: ą, ę, į, ų, ą, ę, į, ų, ė, ū, č, š, ž.
These characters are essential for proper Lithuanian orthography - changing them completely alters meaning. For example:
- mėta (mint) vs meta (throws)
NFD vs NFC: Unicode Normalization Forms
When working with Lithuanian text digitally, understanding Unicode normalization becomes crucial, especially for the characters with diacritics.
What are NFD and NFC?
NFC (Normalization Form Composed)
Characters are represented as single units
ėis stored as one Unicode character: U+0117This is the canonical and most compact form
Most common in practice and recommended for most uses
NFD (Normalization Form Decomposed)
Characters are separated into base letter + combining mark
ėis stored as two characters:e(U+0065) + combining dot above (U+0307)Useful for text processing and linguistic analysis
Takes more storage space
Example with Lithuanian Text
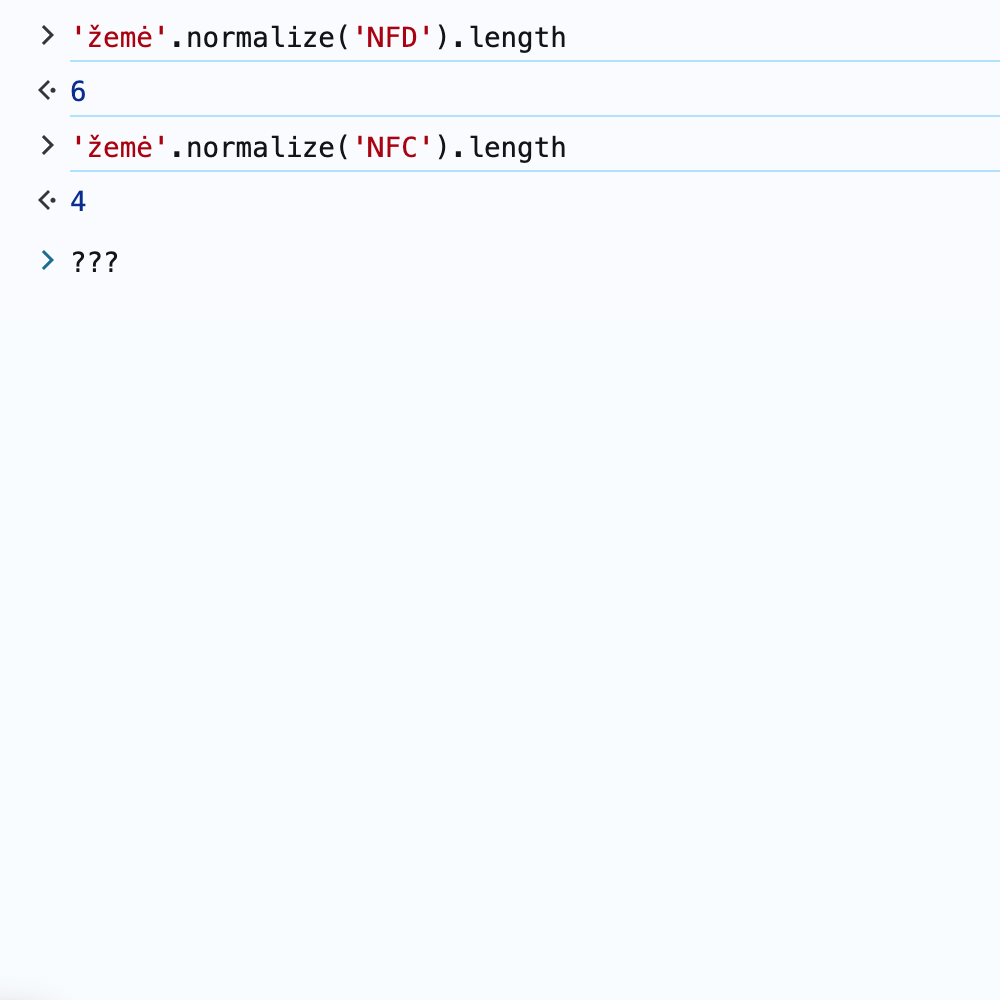
Let's take the word "žemė" (earth):
In NFC:
ž (U+017E) + e (U+0065) + m (U+006D) + ė (U+0117)
= 4 characters
In NFD:
z (U+007A) + ◌̌ (U+030C) + e (U+0065) + m (U+006D) + e (U+0065) + ◌̇ (U+0307)
= 6 characters
Why Does This Matter?
String Comparison: "ė" in NFC ≠ "ė" in NFD at byte level, even though they look identical
Search & Sort: Without normalization, searches might fail to find matches
Database Storage: Consistency is crucial for proper indexing and retrieval
Practices for Lithuanian Text
Use NFC as your default normalization form
Normalize before comparing strings from different sources
Be aware that filenames might get normalized automatically by the OS
When processing user input, normalize to a consistent form first
Example
const textNFC = "žemė"; // NFC form
const textNFD = textNFC.normalize('NFD');
console.log(`NFC length: ${textNFC.length}`); // 4
console.log(`NFD length: ${textNFD.length}`); // 6
console.log(`Visually equal: ${textNFC === textNFD}`); // false
const backToNFC = textNFD.normalize('NFC');
console.log(`Normalized back: ${backToNFC === textNFC}`); // true
Conclusion
Lithuanian's rich use of diacritics makes it an excellent case study for Unicode normalization. While both NFC and NFD represent the same text visually, choosing the right form and handling normalization consistently is essential for correct text processing, in applications dealing with Lithuanian content or any other containing diacritic letters.