Building a Lithuanian Law Assistant with LLM and RAG (part 2)
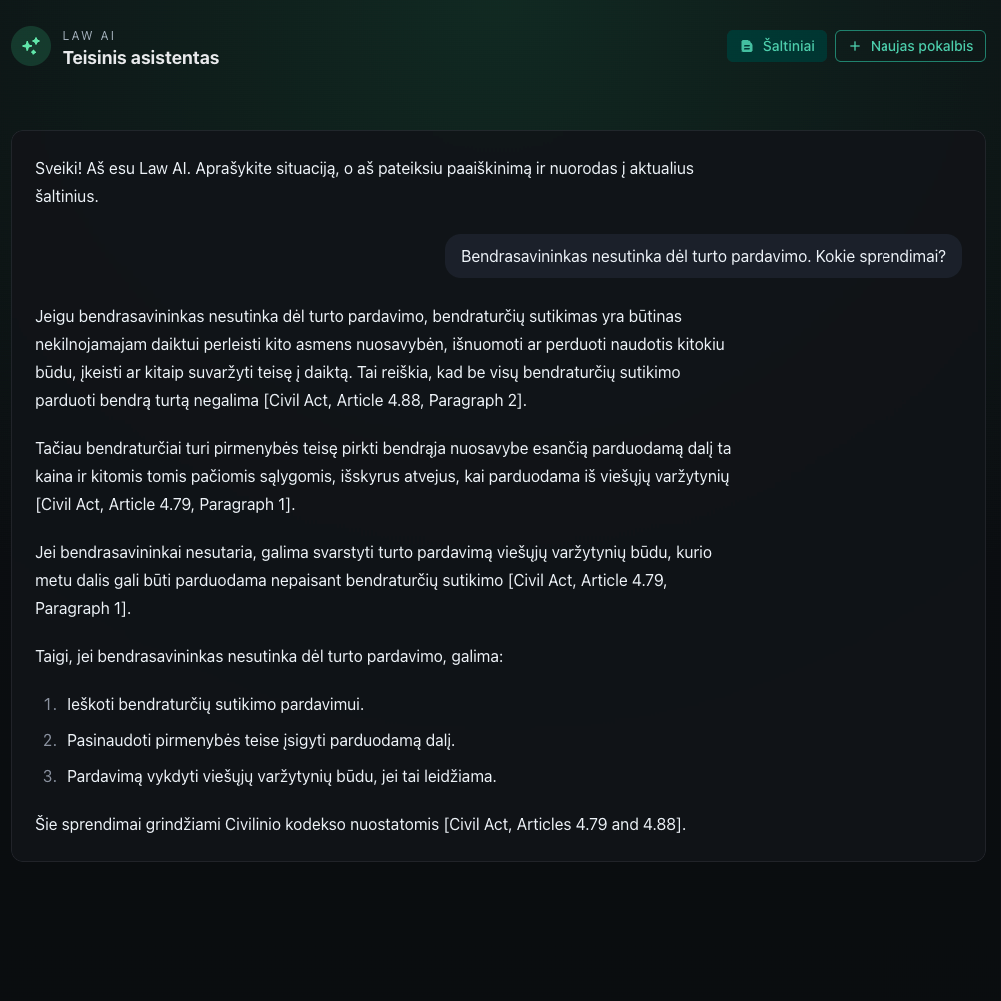
I continue building a Lithuanian AI law assistant. I already have a POC with 4 laws chunked and loaded to the database with semantic retrieval. Is it useful? A bit. It can look up articles — it is easier than just opening and searching with Cmd (Ctrl) + F in a browser. It...
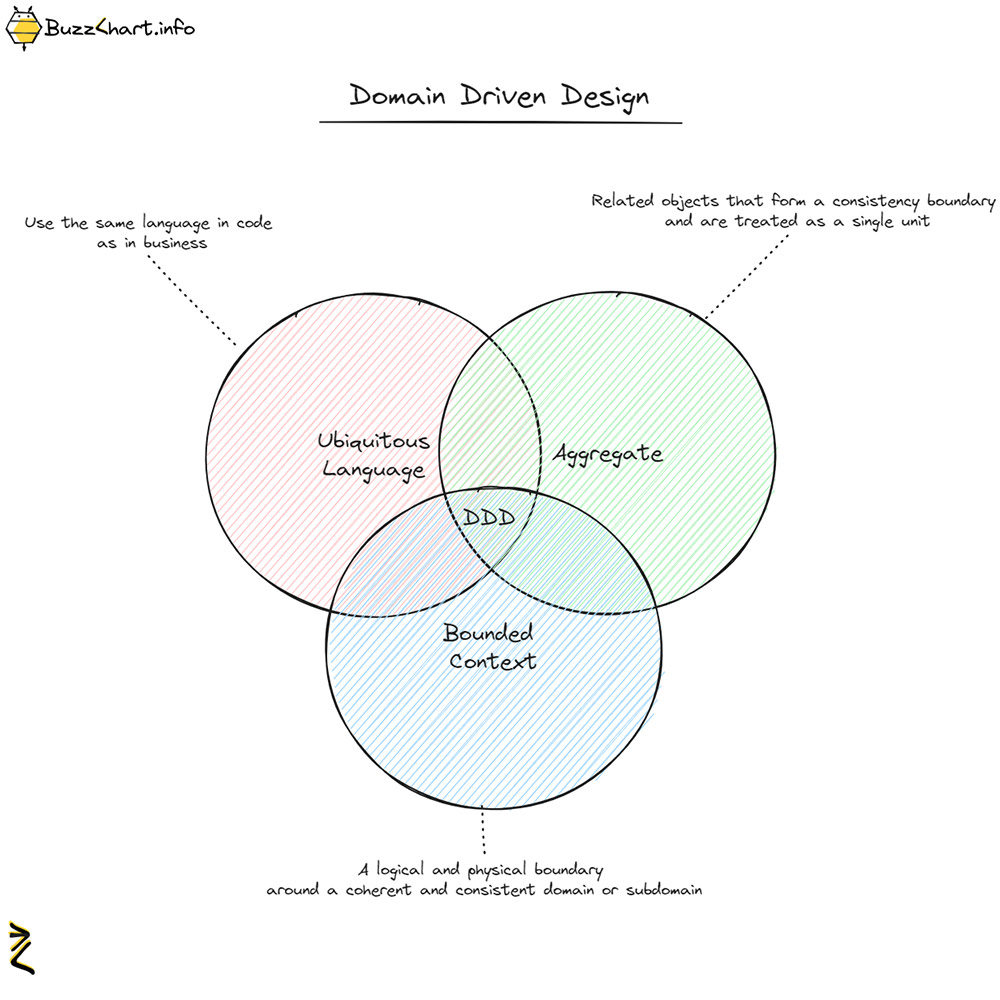
Related concepts: Building a Lithuanian Law Assistant with LLM and RAG (part 1) , RAG , Domain Driven Design , Normalizing Diacritics in Lithuanian .
Introduction
I continue building a Lithuanian AI law assistant. I already have a POC with 4 laws chunked and loaded to the database with semantic retrieval. Is it useful? A bit. It can look up articles — it is easier than just opening and searching with Cmd (Ctrl) + F in a browser. It collects multiple articles into one LLM context and can summarize them. It is already better than plain search. But it is the tip of the iceberg compared to what is really useful beyond simple law search.
Lithuanian Legal System
The Lithuanian law system is hierarchical. It contains multiple documents that are hierarchically related. For example, the hierarchy is: Constitution > Code > Law > Government resolution > Minister order > other less important documents.
Precedents can override law articles. When a legal document (a law or code is a type of document) has an ambiguous interpretation of an article or paragraph, a court decision can clarify it and apply that clarification, removing the ambiguity. The court may even override what is written in the legal document. This is called precedence. This precedence is referenced later in cases related to that article (or paragraph).
Courts also have a hierarchy: Constitutional Court > LAT > Highest court depending on legal domain.
Because the legal system is hierarchical and precedent-driven, simple semantic search fails to resolve precise references.
What is wrong now?
My application currently has multiple disadvantages important for AI assistant applications:
Lack of context: I do not want to delegate missing parts of required terms or concepts to the LLM, because it may be incorrect. Most probably the LLM was not trained on the latest legal documents and is not able to resolve what is fine for driving 11 km/h over the speed limit. If you prompt the LLM explicitly, it will omit its own judgement and interpretation of missing terms. Then the answer will not be complete and will serve only as a dictionary.
Ambiguous context: Semantic search can find related (similar) terms, but this does not mean these terms are related in the context of the question. Having articles in the context for both selling drugs and possessing them can produce a misleading summary. This is worse than providing no answer at all.
Too much context: Similar to Ambiguous context. Another drawback of an overloaded context is that the LLM gets dumb. Different LLMs have different context windows, but all of them have a threshold beyond which they get "dumb" and may miss instructions. Assuming the LLM will handle all context regardless of size is an incorrect assumption.
What is important?
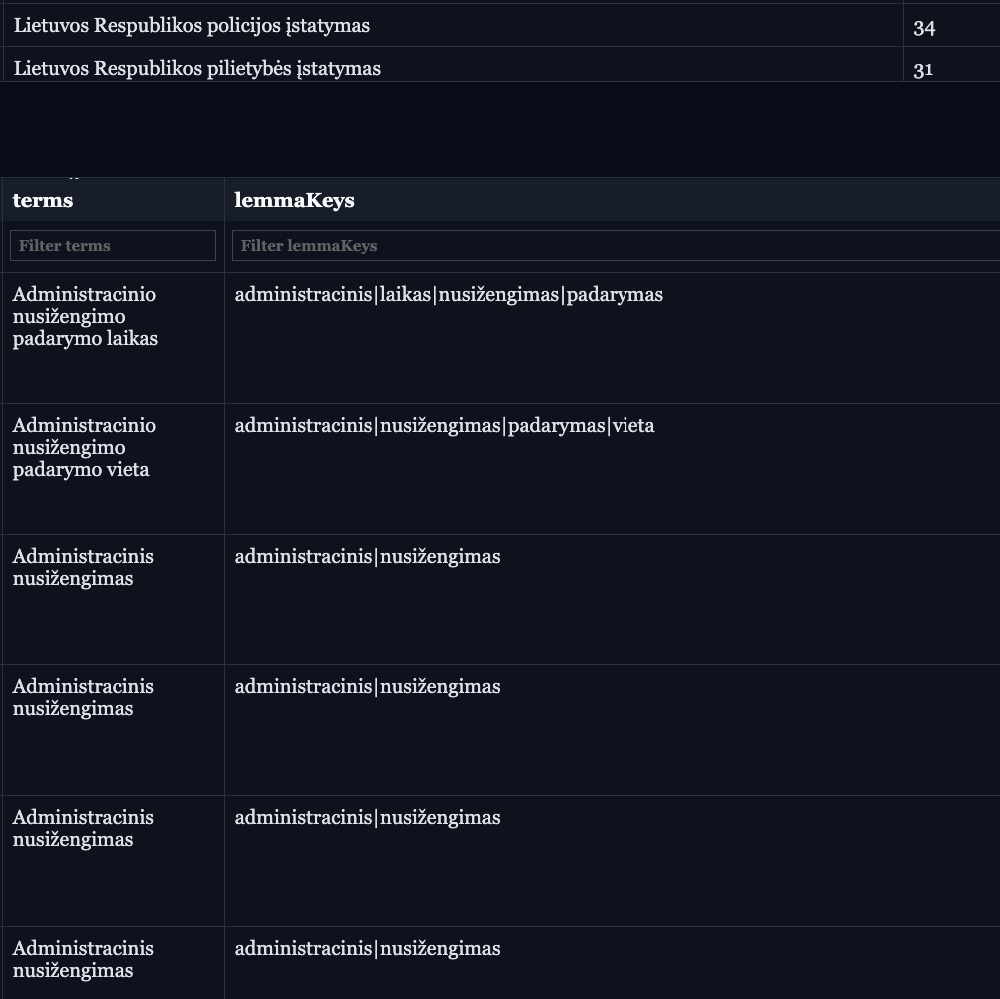
Data. Data and how I split, label, and retrieve it. Questions I need to answer:
How granular is a chunk? What is the smallest domain unit used in a chunk?
What if it is too small? Should I combine chunks for better context?
How big is the data denormalization problem?
What if the content for a chunk is too big?
How do I retrieve these chunks?
How are these chunks related and connected?
In this writeup I answer: what is the smallest domain unit, how chunks are related via concept edges, and how the graph is structured. Deferred: the denormalization problem, chunk size limits, and combining small chunks.
So what
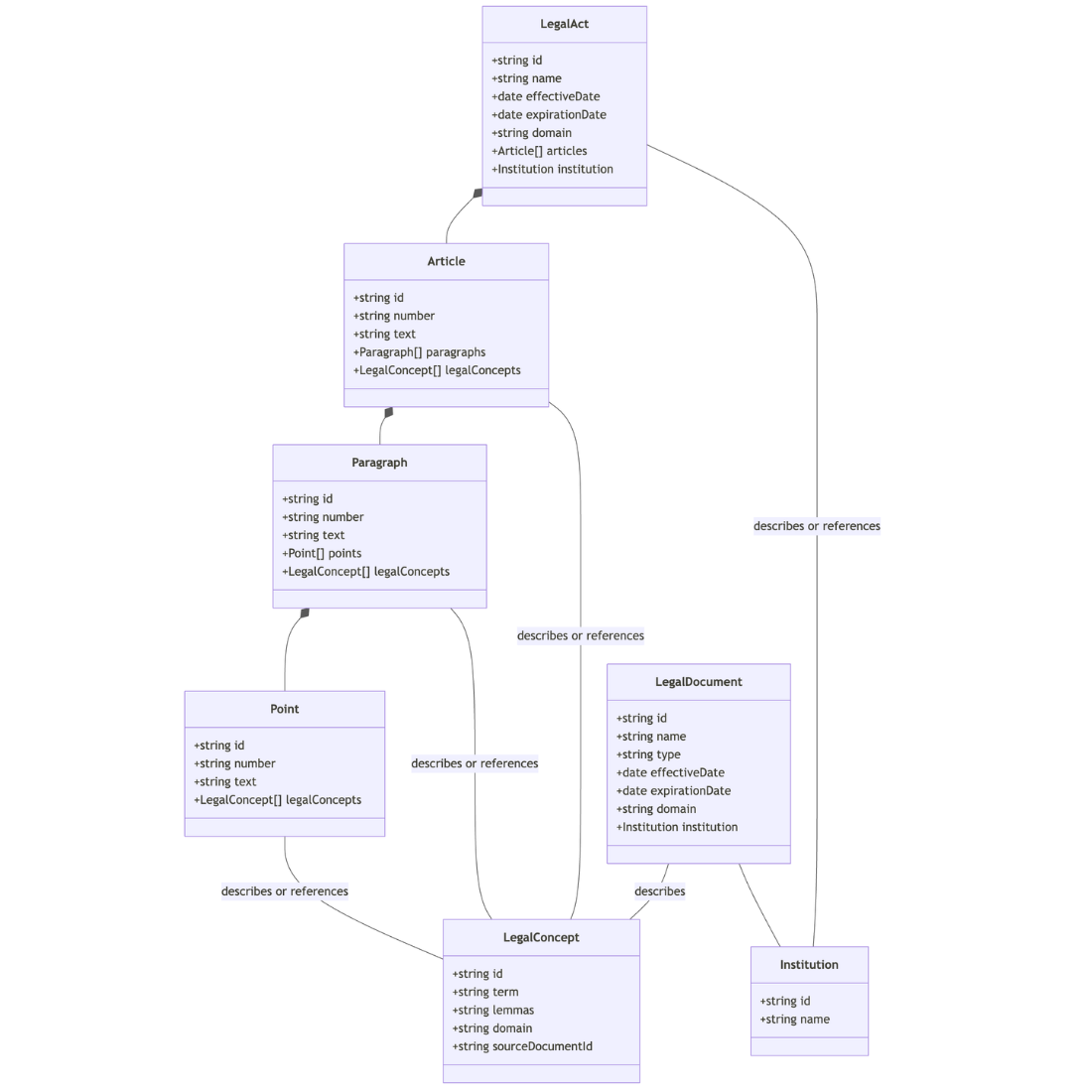
The decision I've made is architectural: connect legal document chunks into a graph, where edges are the legal concepts referenced in those chunks. Every chunk will be a domain object with unique properties allowing search and filtering with high precision.
Why graph over a flat vector store? Flat vector store answers "what is similar". Graph answers "what is connected". For the legal domain this matters because law is a reference system — every article points somewhere. Semantic similarity finds articles about drugs. Graph traversal finds the exact definition of drugs that applies in this specific legal context, the threshold that defines a large amount, and the institution responsible for updating it. This directly solves all three problems listed above: missing context is filled by graph traversal, ambiguous context is reduced by following explicit references instead of similarity, and context size is controlled because I only pull what is reachable via edges.
My chunks
The Lithuanian legal domain contains documents. Documents are related, which creates a graph of documents connected by edges. What is an edge in that domain? I've selected some edges for my MVP — the most important ones, as I understand them, are concepts.
A concept is a definition explained and detailed in the same document or in a related document. For example, article 241 of the Criminal Code defines responsibility for drug dealing. It references the concept "drugs". "Drugs" is defined in a separate article, which points to a Government resolution maintaining the list. The resolution points to a minister order with specific substances and thresholds. So the graph path is: article 241 → concept "drugs" → definition article → resolution → order. When a user asks "what is the penalty for selling drugs", I can walk this graph and pull all relevant chunks instead of relying on semantic similarity alone.
Changing a law is an expensive and lengthy process, which is why amounts and units referenced in definitions may be described in external documents that can be updated more frequently.
Concepts may be:
described in the document
described in an external document
described as a definition
described as a list of definitions
described with thresholds
referenced to the document
referenced to an external document
Concepts are edges for chunks (parts of a legal document stored separately in the database).
I will have the following entities in my database: legal act > article > paragraph > point, and legal document. All of them will be connected via a concept entity.
I decided to go to paragraph and point level. Article is too big — one article can cover multiple unrelated topics. Paragraph is the smallest unit that still makes sense as standalone text. Points within paragraphs will be stored separately only if they contain independent legal meaning, for example a definition or a threshold.
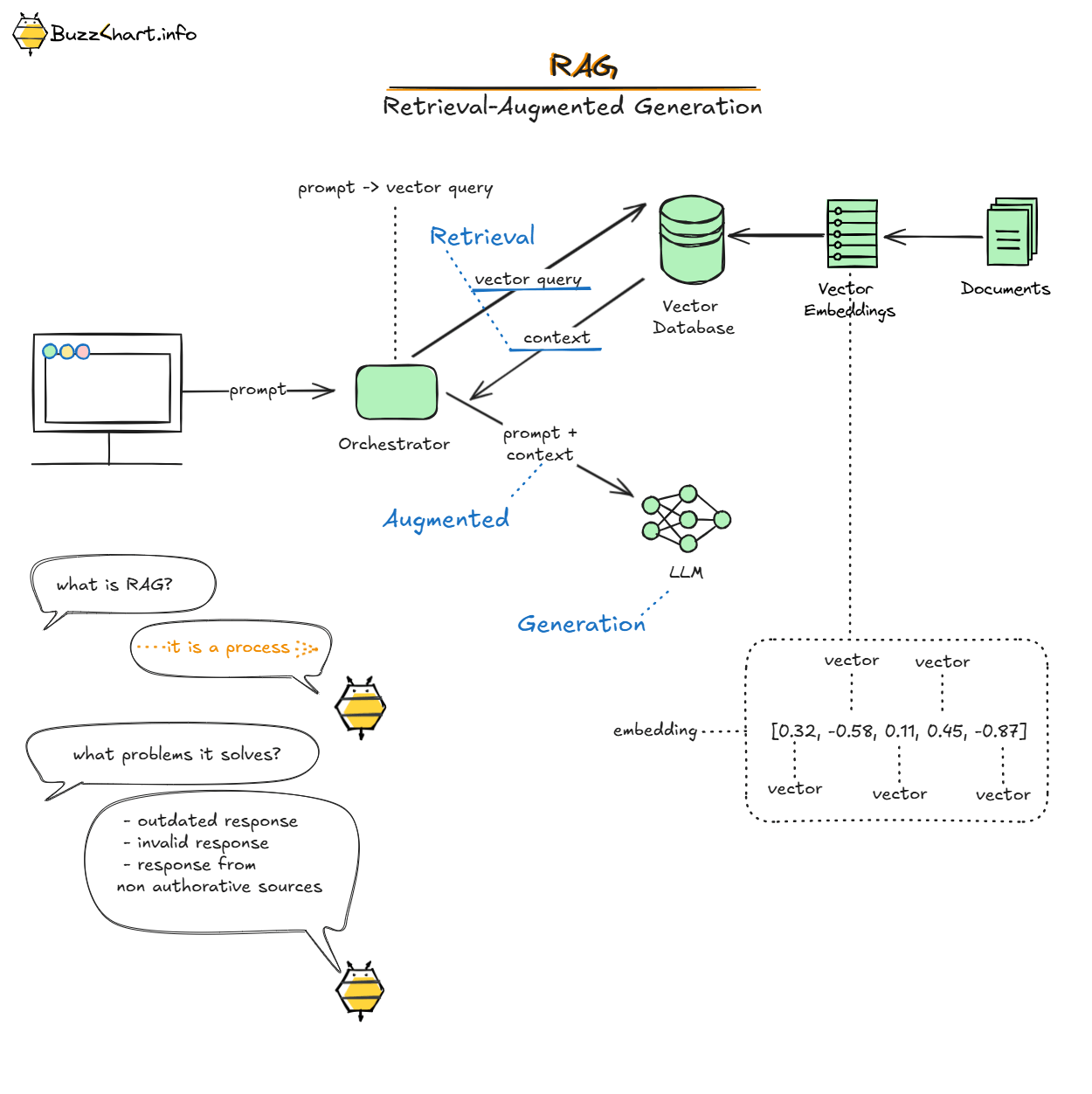
Retrieval works as follows: start with semantic search to find the most relevant chunk, then expand via concept edges — pulling all chunks connected to the concepts referenced in that chunk. Filter by document hierarchy and legal domain. This way context is precise and traceable, not just similar.
For now I do not have precedents as concepts in my model, but adding them later will not break this domain model.
MVP scope
In my MVP I want to take one domain — "baudžiamoji teisė" (criminal law) — and collect all legal documents in this domain. Lithuanian legal acts are publicly available on e-tar.lt and infolex.lt. Collection will be semi-automated. It will include Government resolutions, minister orders, and court decisions with legal cases. After all data is collected, I will build a retrieval pipeline and plug it into the chat application, which is already partly done from the POC.